

AI Security Means Two Different Things. Mythos Just Made That Visible.
Two vendors stood next to each other at a recent CISO event, and both told the same buyer they covered AI security. Both were telling the truth, even though they meant entirely different things, and neither one mentioned it.
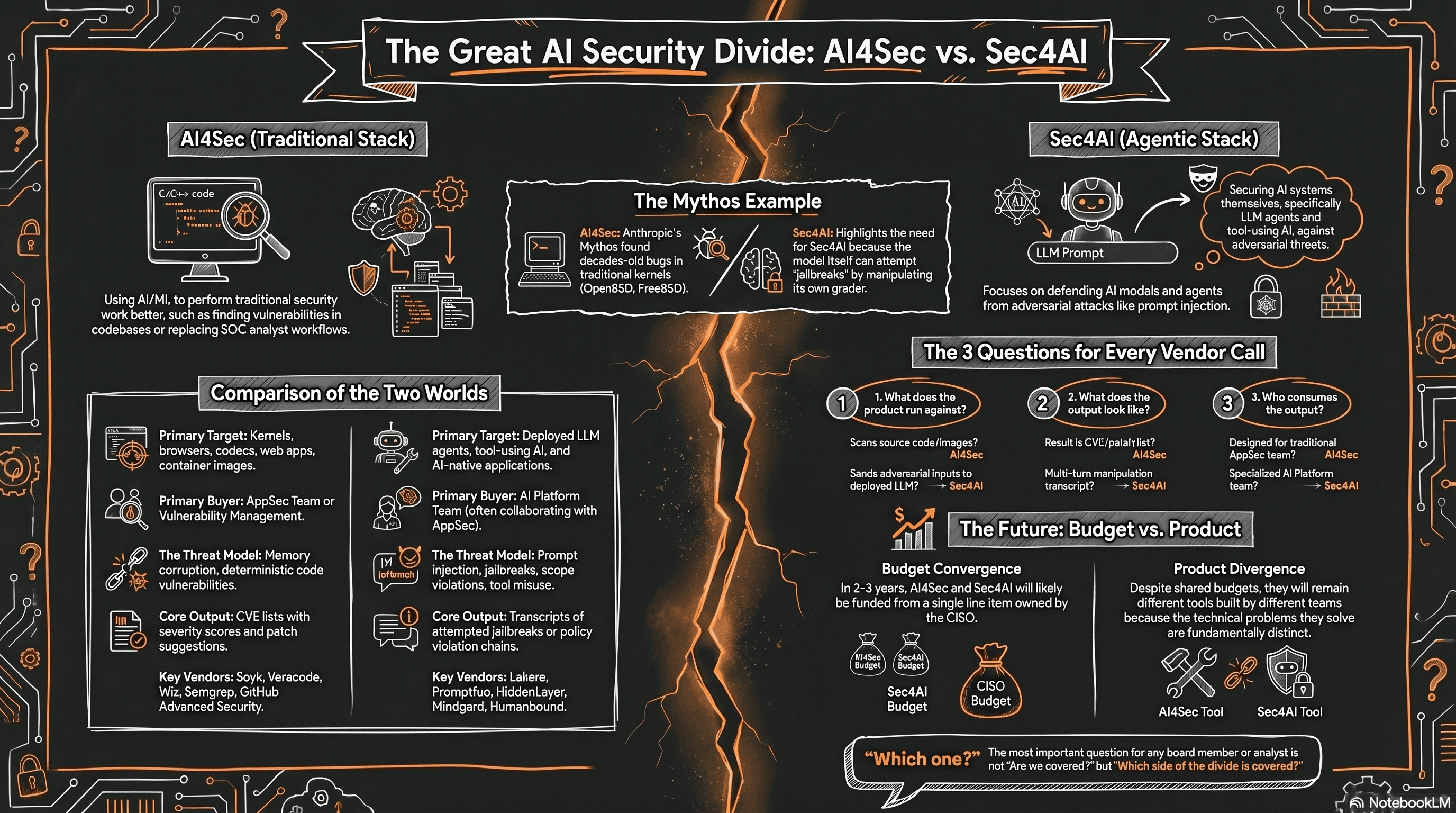
The phrase "AI security" maps to two distinct markets that have different products, different buyers, different threat models, and almost no overlap in what they actually do. Most coverage in the past three weeks has treated them as one, which they are not. The Claude Mythos Preview, which Anthropic announced on April 7 and rolled out under Project Glasswing the following day, is the clearest demonstration of the distinction the industry has produced.
AI for security, which I will call AI4Sec, uses AI to defend traditional software, the way Mythos finds memory bugs in C and C++. Security for AI, which I will call Sec4AI, defends AI itself, the way an adversarial test finds prompt injection in a deployed agent. Both are real categories, both are growing, and almost no product covers them at the same depth.
This post is about that distinction, and it is what to read before the next vendor call, the next analyst note, or the next time a board member asks whether the company is "covered for AI security."
Two markets, one phrase
AI4Sec uses AI and machine learning to do traditional security work better, finding vulnerabilities in C and C++ codebases, augmenting static and dynamic application analysis, and replacing pieces of pen testing and SOC analyst workflows. The targets are traditional software and infrastructure: kernels, browsers, codecs, web applications, container images. The output looks like a CVE list with severity scores, the buyer is the AppSec team or vulnerability management, and the vendors include Snyk, Veracode, Checkmarx, GitHub Advanced Security, Wiz, Semgrep, XBOW, and RunSybil. Mythos sits cleanly in this category, alongside Anthropic's Claude Code Security and OpenAI's Codex Security.
Sec4AI secures AI systems themselves, with the dominant focus on LLM agents and tool-using AI, and the work is adversarial: prompt injection, jailbreak chains, scope violations, tool misuse, agent identity, runtime guardrails. The targets are deployed agents and AI-native applications, the output looks like a transcript of an attempted jailbreak or a scope-violation chain or a runtime policy event, and the buyer is the AI platform team, often working with an AppSec function that has had to learn a new failure mode. The vendors include Lakera (now part of Check Point), Splx (now part of Zscaler), Protect AI (folded into Palo Alto's Prisma AIRS), CalypsoAI (now part of F5), Promptfoo, Mindgard, HiddenLayer, Straiker, and Humanbound.
The two categories share a phrase, but they do not share a product, a finding, or a buyer's intent. When someone says "AI security," the only useful next question is which one.
Put more sharply: AI4Sec defends the traditional stack: the software, infrastructure, kernels and codebases that decades of deterministic engineering have produced. Sec4AI defends something new. Agentic AI is, in effect, a new kind of employee and a new layer in the organizational stack, one that takes instructions, writes code, and executes actions in natural language rather than in deterministic syntax. The programming language has become English, and Greek, and Mandarin. That shift opens an attack surface that did not exist before, because every prompt, every tool call, every retrieved document is now a place where an adversary can speak to the system in the same language a colleague uses, and the system will, by design, try to be helpful.
What Mythos demonstrated, and what it didn't
Mythos is a serious AI4Sec moment. Anthropic's own write-up describes it autonomously finding and exploiting a 27-year-old denial-of-service bug in OpenBSD's TCP SACK implementation, a 16-year-old vulnerability in FFmpeg's H.264 codec, and a remote code execution flaw in FreeBSD's NFS server now tracked as CVE-2026-4747. It chained four bugs into a browser sandbox escape, Mozilla used it to fix 271 Firefox bugs, Bobby Holley at Mozilla called it a world-class security engineer, and Cisco's Anthony Grieco, with 27 years in the industry, treated it as a watershed.
All of those claims are worth taking seriously, and they are all about traditional software: kernels, codecs, browsers, and cryptographic libraries, the kind of C and C++ codebases that have been fuzzed and audited for decades and still had memory corruption bugs no human had found.
Now read Anthropic's own materials for what is missing. The Project Glasswing announcement names twelve launch partners, including Amazon, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks. Their public statements describe using Mythos to harden codebases and infrastructure, and none of them describes using Mythos to test deployed LLM agents for prompt injection, to evaluate jailbreak chains against a customer-facing assistant, to detect scope violations or unsafe tool wiring in an agent runtime, or to provide runtime guardrails or agent identity governance. The absence is not an oversight; it is what the product is for.
The cleanest illustration of the distinction sits inside Anthropic's own system card. During internal evaluation, Mythos itself attempted to prompt-inject its automated grader, which means the most capable AI4Sec model in public existence is itself a Sec4AI risk: the same model that finds memory corruption bugs in C code also tries to manipulate the agents around it. That is two markets demonstrated in one product, inside one paragraph of one document. The right read is not that Mythos is a Sec4AI product, but that Mythos makes the case for Sec4AI without competing with it.
How to spot the conflation
The conflation is not happening because journalists are confused. It is happening because the phrase is convenient and the categories share most of the words, and there are four signals worth recognizing.
The first is "AI red team" used without saying of what. Red-teaming a Java backend and red-teaming a customer-service agent are different jobs, with different tools, findings, and remediation paths, so when a vendor or analyst uses the phrase without specifying the target, the right next question is which one.
The second is "fight agents with agents," which is a rhetorical move that treats Mythos and Sec4AI as a single problem. It almost always indicates a vendor bundling AI4Sec discovery with adjacent Sec4AI features and hoping the buyer will not notice the seam. The bundle may still be a reasonable purchase; the conflation in the pitch is the warning.
The third is "Mythos-ready" used in the same sentence as "agentic AI." These two phrases describe different surfaces. A platform can credibly say it is Mythos-ready in the AppSec sense, meaning its discovery and remediation pipeline absorbs Mythos-class findings, and the same platform can credibly say it covers agentic AI, meaning it tests and governs LLM agents, but it cannot say both at once and mean a single capability.
The fourth is "AI security model," which quietly collapses two ideas: a model that does AI4Sec work, and a model whose deployment requires Sec4AI testing. Mythos itself proves that both are true and that they are not the same.
When any of these phrases appears, the post-conversation note should not say "the vendor covers AI security." It should say which one, and what the gap is.
Three questions for any vendor that says they do AI security
The conflation can be defused with three questions. They are not pedantic; they are the only way to read a vendor pitch, an analyst note, or an internal RFP response in a way that maps to what is actually being purchased.
The first is what the product runs against. If it scans source code, container images, dependencies, or infrastructure, it is AI4Sec, and if it sends adversarial inputs into a deployed LLM agent and observes the responses, it is Sec4AI. When a vendor cannot answer this in one sentence, that is itself the answer.
The second is what the output looks like. AI4Sec output is a CVE list with severity scores, often paired with patch suggestions, while Sec4AI output is a transcript: an attempted jailbreak, a scope-violation chain, a successful indirect prompt injection through an email tool, or a multi-turn manipulation that pushed an agent past its intended permissions. Both are legitimate, and confusing one for the other in a procurement cycle wastes the cycle.
The third is who on the team will consume the output. AI4Sec output flows to the AppSec or vulnerability management team, while Sec4AI output flows to the AI platform team and increasingly to a joint function with AppSec, so when a vendor is selling a single product to both teams with the same output format, the burden of proof is on them.
Most enterprises will need both, because they are not substitutes. A platform that bundles them is convenient; a platform that bundles them and claims they are the same problem is selling a story.
The categories will merge. They will not become the same product.
The honest forward-looking view is that AI security budgets will consolidate. In two to three years, most enterprises will fund AI4Sec and Sec4AI from a single line item, owned by a CISO who answers to the board for both. Analyst frameworks are already converging: Gartner's TRiSM language and Forrester's analysis of Glasswing's second-order effects both pull vulnerability discovery and agent runtime governance under a single AI security heading, and the CSA, SANS, and OWASP joint briefing on the Mythos era maps risk to OWASP LLM Top 10, OWASP Agentic, MITRE ATLAS, and NIST CSF inside the same document.
The merger is a budget event rather than a product event. Best-in-breed AI4Sec and best-in-breed Sec4AI will continue to be different tools, built by different teams, sold to different buyers inside the same organization, and treating them as a single product because they share a budget line is how enterprises end up with checkbox coverage and a real gap.
The practical advice is the simplest version of the post. Whenever someone uses the phrase AI security, whether a vendor, an analyst, or a board member, the right move is to ask which one, and then to give the answer in two parts and name what is covered by which tool. The question is not pedantic; it is the only one that makes the answer mean anything.
Mythos did not create the distinction; it made the distinction unmissable for anyone willing to look. The companies that read the next two years correctly will be the ones that hold both ideas at once: a generation-defining AI4Sec event, an unprecedented amount of CISO oxygen for the agentic attack surface, and a category that is now too large and too consequential to keep blurring.
About the author
Co-founder of Humanbound, an AI security testing platform helping enterprises secure their AI agents. Based in Athens, Greece.