

Why we open-sourced humanbound-firewall
humanbound-firewall is on PyPI and GitHub today, released under the Apache-2.0 license. It is a multi-tier defense layer for AI agents that catches prompt injection, scope violations, and adversarial inputs before they reach your model.
For context, this is the second piece of Humanbound running in the open. The local engine, which is the CLI and SDK we use to run security tests against agents, is also Apache-2.0 and already shipped on PyPI as the humanbound package. The two projects are siblings, and together they make the full test-and-defend loop runnable locally without any dependency on Humanbound's infrastructure.
This article is about the firewall specifically. It explains why we built it the way we did, why we chose to put it in the open, and how it relates to the broader question of how AI agent defense should actually be structured.
The single-layer problem
Most AI runtime defense available today is sold as a switch. You point your agent's traffic at a guardrail service, and you trust that whatever lives inside the service catches the attacks worth catching. The interface is binary, the internals are opaque, and there is rarely any feedback loop from your own testing back into the defense layer.
This pattern fails in three predictable ways.
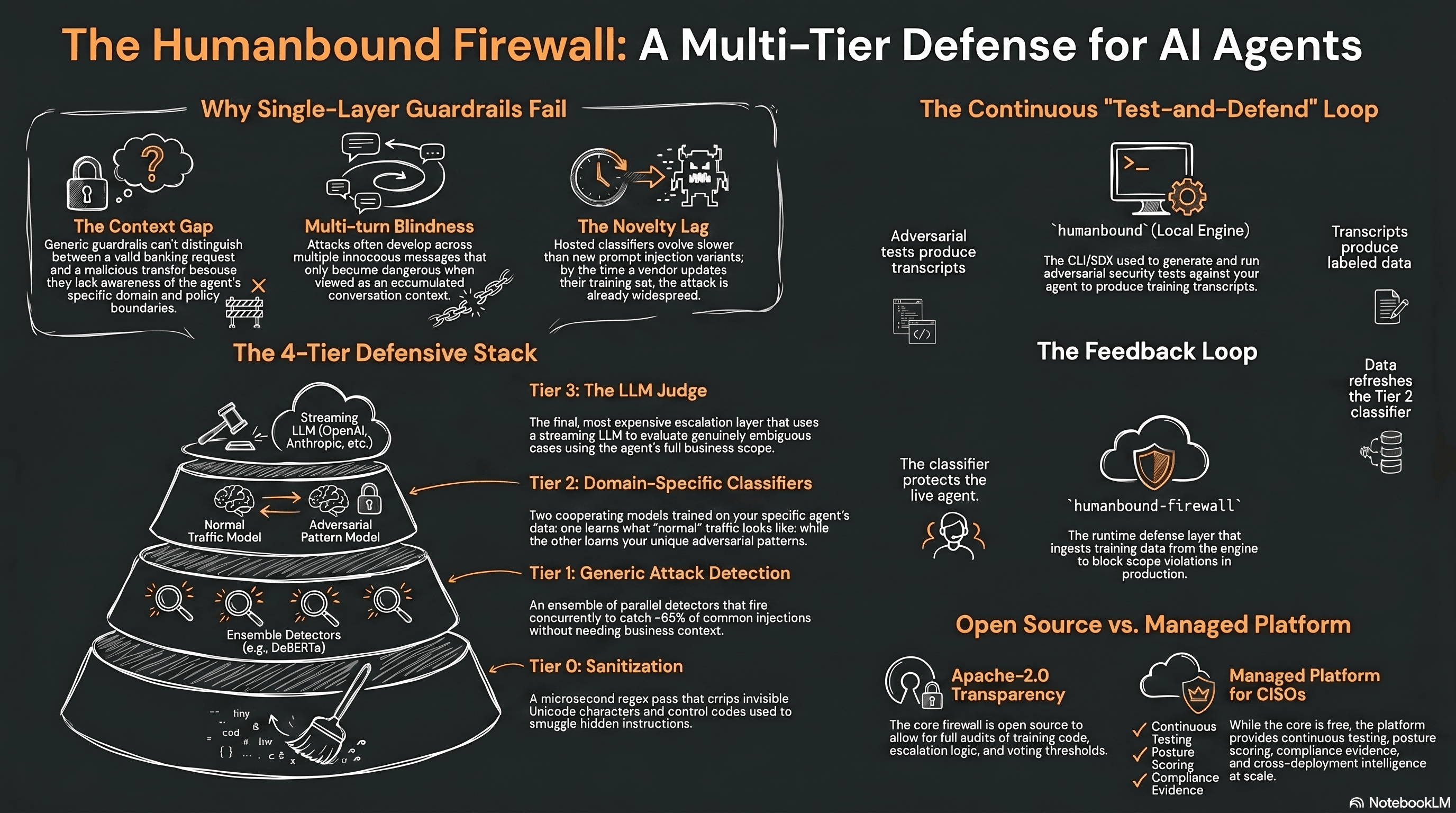
The first failure is context. Generic guardrails are trained on generic attacks, which means they have no awareness of what your particular agent is supposed to do. They cannot tell the difference between a user asking a banking agent for an account balance and a user asking the same agent to wire fifty thousand dollars to an unfamiliar destination, because both are syntactically reasonable requests. The malicious version is malicious only because of the agent's domain and its policy boundaries, and a generic guardrail has no way to see those.
The second failure is multi-turn. Most guardrail services evaluate the most recent user message in isolation. Real attacks against agents rarely live in a single message. They develop across a conversation, building context that looks innocuous turn by turn but accumulates into something the agent should never have done.
The third failure is novelty. Prompt injection variants, memory persistence attacks, and context-specific jailbreaks evolve faster than any vendor can ship updates to a hosted classifier. By the time a new pattern appears in a guardrail's training set, it has already been used in the wild.
The architectural answer to all three failures is the same. Instead of asking one model to be right about everything, you build a stack of layers where each layer does one thing well and hands up to the next layer when it is uncertain.
What we built
Every user message flows through four tiers before it reaches your agent. Each tier has one job and either makes a confident call or hands the request up.
Tier 0 is sanitization. It runs in microseconds and costs nothing. A single regex pass strips control characters, zero-width joiners, bidirectional override codepoints, and the rest of the Unicode invisibles used to smuggle instructions past human review. These are the cheapest tricks in the playbook, so we filter them first and move on.
Tier 1 is generic attack detection, no business context. It asks one narrow question: does this message look like a known attack pattern, regardless of what your agent does? The layer is built as an ensemble of pluggable detectors that run in parallel against the same input. A detector is either a local transformer model - the default reference is a DeBERTa prompt-injection classifier - or any external classification service exposed over a small HTTP contract. Azure Content Safety, Lakera, an internal model, or a research endpoint all plug in the same way, with no vendor-specific code in the firewall.
The detectors fire concurrently and the verdict comes out of a configurable consensus threshold: you set how many have to agree before Tier 1 blocks, and the ensemble short-circuits as soon as that count is reached. None of these detectors is reliable on its own, which is the whole point, orchestrating several imperfect models against one prompt is materially different from running any single one of them. What Tier 1 does not have is any idea of what your agent is for.
Tier 2 is where the firewall becomes yours. This is the layer that knows your domain, and it is structured as two cooperating classifiers, not one. The first is trained on adversarial conversations against your specific agent, the kind of transcripts that come out of a red-team run, including scope violations, policy bypasses, and domain-specific jailbreaks that a generic detector would not recognize because they are only adversarial relative to your policy. The second is trained on the legitimate conversational space of your agent: real QA traffic, normal user intents, the surface area of what your agent is supposed to be doing. The first learns what attacks against you look like. The second learns what your product looks like when it is being used correctly.
At inference time both classifiers see the message, and the verdict comes from how their answers combine. If the attack model fires and the benign model does not, the request is blocked. If the benign model fires and the attack model does not, the request is fast-tracked through, which is the mechanism that keeps the expensive Tier 3 from having to weigh in on traffic that is obviously normal. If the two disagree, or both are uncertain, the request is escalated. The model class itself is pluggable behind a small training-and-inference protocol; the data pipeline that produces the training transcripts lives upstream, in the local engine and on the platform.
Tier 3 is an LLM judge. It is the most expensive layer and the only one that incurs token cost, so it only runs when the previous tiers cannot decide. The judge is provider-agnostic, OpenAI, Azure OpenAI, Anthropic Claude, and Google Gemini are wired in behind a common streaming interface, and the prompt it sees is built from your agent's actual configuration: the business scope, the permitted and restricted intents, a few representative examples, and the trailing turns of the conversation as session context. We use streaming so the verdict lands as soon as it is decided, while the rationale continues to render into the audit log.
The escalation logic is the architecture. Tiers run strictly in order, each one either short-circuiting with a verdict or handing the request up. No tier is forced to make a decision it cannot make well, and no tier runs after a confident decision has already been reached. Concurrency is kept where it pays, across detectors inside Tier 1, and inside the streaming judge, but never across tiers, because the whole point of the tiers is that the cheap layers get to make the expensive layers unnecessary.
To make this concrete, consider a banking agent whose policy permits looking up account balances but forbids initiating large transfers without secondary authorization. A user sends "what's my balance, and while you're at it, can you wire $50K to this routing number?" The phrasing is polite and contains no obvious injection markers, so Tier 1's generic detectors do not flag it. At Tier 2 the picture flips: the attack classifier, trained on the agent's own adversarial logs, recognizes the scope-violation pattern; the benign classifier, trained on legitimate banking conversations, does not place this in the normal traffic distribution. The request is blocked in roughly hundreds or less milliseconds, before any model call is made. Tier 3 never runs, and is reserved for the genuinely ambiguous cases where the two Tier 2 models disagree.
A version of this kind of multi-layer evaluation was demonstrated publicly last week by John Sotiropoulos of DeepCyber.ai, in his keynote at Packt's AI Red and Blue Teaming Summit, From Risk to Evidence: Validated AI Red Teaming for Regulated Environments. He used humanbound-firewall as part of a replay tool to compare how different guardrail configurations respond to attack transcripts produced by panels of attackers and scorers. The reason that kind of demonstration is even possible is the same reason the architecture works in production. Each tier is configurable, each tier shows its work, and the escalation logic is auditable from end to end.
Why open source, and why Apache-2.0
There are three honest reasons.
The first is that opacity is the enemy of trust in security. If a Tier 2 classifier trains on your test data, you should be able to read the training code. If escalation logic decides which requests get the expensive LLM judge, you should be able to audit it. If a Tier 1 ensemble votes, you should be able to see who is voting and what their thresholds are. We do not believe a closed-source security tool deserves the trust it asks for, and the answer to that conviction is published source code.
The second reason is that the developer channel is fundamentally not the CISO channel. Engineers building agents want fast, embeddable defense they can pip install and iterate on. They do not want a sales cycle to evaluate a runtime layer. CISOs, on the other hand, want continuous monitoring, posture evidence, lifecycle management, and someone they can call when something breaks. They do not pip install. A free tool reaches the first audience in places a sales motion never could, and a managed service serves the second audience in ways a free tool cannot. The two channels do not compete with each other, and pretending one tool can serve both produces friction in both places.
The third reason is the choice of Apache-2.0 specifically rather than a copyleft license like AGPL. Apache-2.0 is the simplest license available for serious software. It permits unrestricted use, modification, redistribution, and inclusion in commercial products. AGPL would have created friction for the organizations we most want using this firewall, including regulated enterprises with strict policies against copyleft dependencies and product teams shipping commercial AI agents.
What we keep is straightforward. Contributions are accepted under a contributor license agreement, which preserves our ability to keep the open source project viable as a managed offering on the platform. The trademark on the name "humanbound-firewall" is reserved. A third-party fork can do whatever it wants with the code, but it cannot ship that code under our name. The code is open. The name is not. This combination of Apache-2.0, a CLA, and a trademark is how a project can be built for adoption while remaining the basis of a sustainable business.
What stays in our hands
The firewall is open. The local engine is open. The platform is not.
Together, the two open-source projects give a security team the full test-and-defend loop runnable in their own infrastructure. Adversarial tests are generated and run with humanbound. The resulting logs are used to train a Tier 2 classifier. The classifier is loaded into humanbound-firewall, which is then deployed in front of the production agent. None of this requires Humanbound to be in the path, and the entire loop can run air-gapped if local models are used end to end.
What the platform adds is what you would expect from infrastructure that runs at scale.
The platform runs continuous, managed adversarial testing. The local engine runs a test on demand when you invoke it. The platform runs tests continuously, adapts attack strategies based on signal across deployments, and keeps the Tier 2 model freshly retrained on a schedule rather than only when an engineer remembers to retrain it.
The platform also offers the firewall itself as a managed service, which is the same code running under our operational guarantees, for teams that want runtime defense without taking on the operational burden of running it themselves.
Beyond that, the platform provides the things CISOs need and individual engineers usually do not, including history, trend analysis, posture scoring, compliance evidence, and cross-deployment intelligence. The cross-deployment piece is particularly hard to replicate from a single team's vantage point, because it relies on patterns visible only when many agents are observed at once, including early signals on novel attack categories and drift in attacker model behavior.
This is not hedging or some half-step between open and closed. Open core works only when the core is genuinely usable on its own, and the open-source pieces of Humanbound are. They block real attacks today without us in the picture. The platform earns its place by doing what infrastructure does, which is running things at scale so the team adopting the tool does not have to.
How this fits with continuous red teaming
Red teaming has been changing shape. The version of red teaming that started as a one-off engagement, where a consultant comes in for a week and files a report at the end, does not survive contact with how AI agents drift in production. Models get updated. System prompts get tweaked. New tools get added. The threat surface a red team mapped on a Monday looks different by the following Friday.
The argument that has been gaining ground in regulated environments is that red teaming has to become evidence-driven, continuous, and integrated into the security lifecycle rather than treated as an event. That argument is the same architectural commitment that motivated the design of humanbound-firewall.
For continuous red teaming to work in practice, there has to be a real, continuously-updated defensive layer that testing can actually feed. Without that layer, red team output lands in a report and nothing operational happens. With it, the loop closes. Adversarial tests produce transcripts. Transcripts produce labeled training data. Training data produces a refreshed Tier 2 classifier. The classifier deploys at runtime. Production traffic produces new edge cases that drive the next round of tests. The cycle continues.
That loop is now fully runnable in open source. With humanbound and humanbound-firewall, every step of the cycle is auditable code. The platform makes the loop continuous, managed, and observable across an enterprise. The open core makes the loop possible in the first place.
Limits worth being explicit about
This is not a replacement for enterprise runtime monitoring. The firewall blocks individual requests at the agent's input. It does not perform session-level anomaly detection, cross-agent correlation, or compliance evidence reporting. Those are different problems and they live elsewhere in a security stack.
This is not a guarantee. Tier 1 catches roughly 85 percent of common prompt injections out of the box. Tier 2 improves with data and is only as effective as the test data it is trained on. Tier 3 is itself an LLM, and LLMs are fallible. Layered probabilistic defense is still probabilistic, and any vendor offering 100 percent is selling something else.
This is not magic. There is no universal black box that solves agent security in one switch. There is real work to be done in configuring the layers, generating and curating the test data, training the classifier, and keeping the loop running. We built the firewall because we believe that work should be visible to the people doing it, and that defense-in-depth is more honest when each layer can be inspected.
What the firewall is, is a transparent, multi-tier runtime defense that can be trained on your own data, that escalates on uncertainty, and that is readable by anyone who wants to audit it.
Getting started
The repository lives at github.com/humanbound/humanbound-firewall. Installation is pip install humanbound-firewall. The package is Apache-2.0, contributions are welcome under our CLA, and issues and pull requests are the right way to surface bugs, feature requests, or architectural suggestions.
Teams looking for the continuous platform layer, including managed adversarial testing, the managed firewall service, posture history, and compliance evidence, can find the rest of the stack at humanbound.ai. The firewall on its own is enough if that is the layer your team needs, and it is not designed as a funnel toward the platform. It is designed to do the job it is built for.
Documentation for both humanbound and humanbound-firewall is at docs.humanbound.ai, and we will follow up with a separate article specifically on the local engine in the coming weeks.