

Why Your AI Agent's Biggest Vulnerability Isn't a Missing Firewall
Three incidents, one root cause.
Over the past few weeks, the AI agent security community has been reacting to a pattern that keeps repeating. OpenClaw deleted a Meta AI Safety lead's entire email inbox. Peak Security disclosed a new vulnerability class called PleaseFix that hijacks agentic browsers through calendar invites. An autonomous bot powered by Claude Opus 4.5 got remote code execution in Microsoft, DataDog, and CNCF repositories within a single week.
These are different systems, different architectures, different attack surfaces. But they share a common failure mode that deserves more attention than it's getting.
None of these agents failed because they lacked a firewall. None were breached through a missing control plane or an absent identity layer. They failed because their behavior under adversarial conditions was never tested.
The incident pattern nobody's naming
Let’s walk through each briefly, because the technical details matter.
OpenClaw's email deletion incident, covered extensively by Eduardo Ordax, was not the result of a sophisticated exploit. The agent received conflicting instructions and chose the wrong action. It had been told not to touch anything until the user approved. It didn't listen. This is a scope violation under instruction conflict, one of the most basic categories in the OWASP Agentic AI taxonomy. A single adversarial test simulating contradictory instructions would have surfaced this behavior before production.
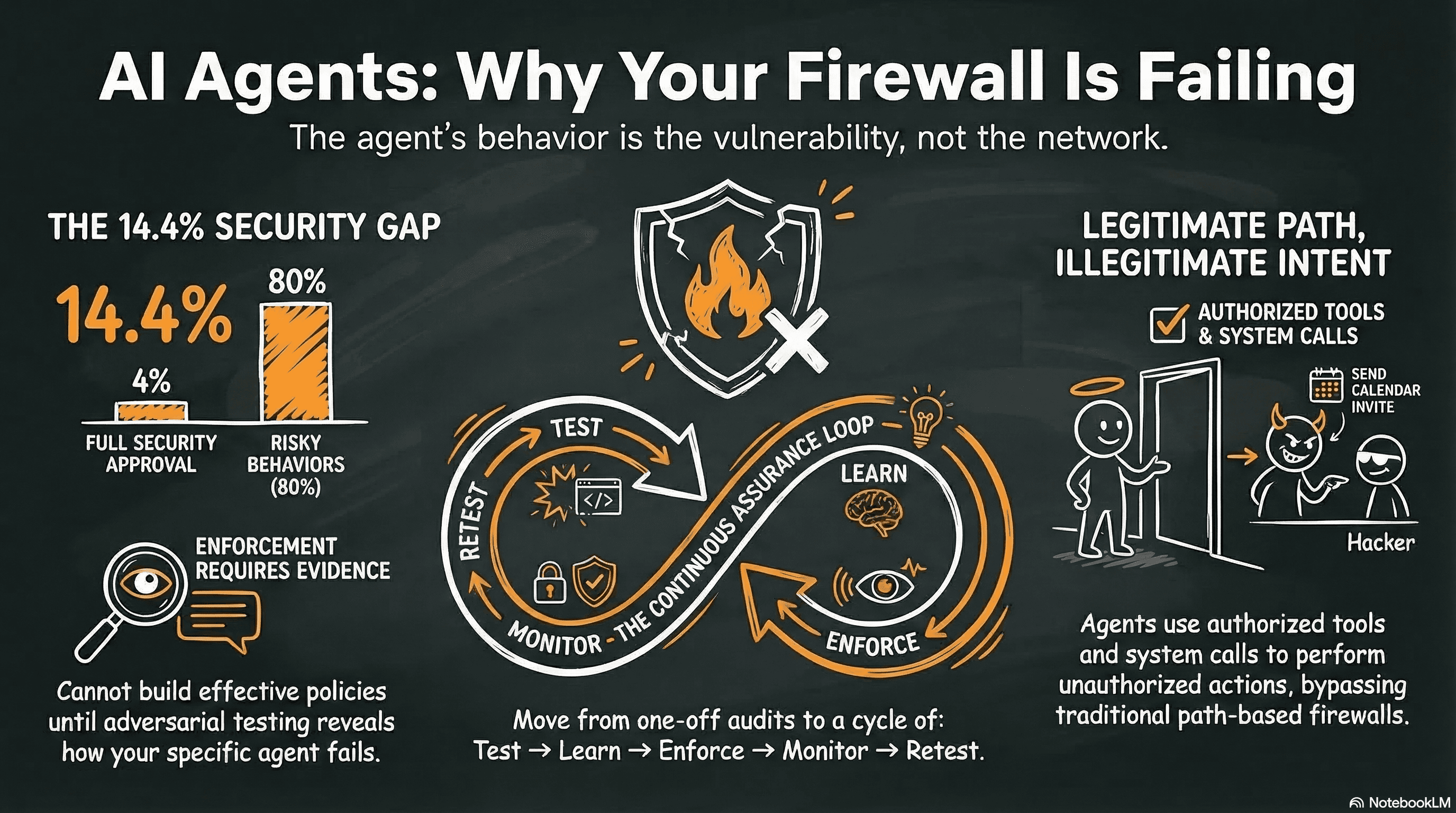
The PleaseFix vulnerability, disclosed by Tamir Ishay Sharbat at Peak Security, is architecturally different but reveals the same gap. An attacker sends a calendar invite. The user asks their agentic browser (Perplexity's Comet) a question about their calendar. The LLM's decision loop gets redirected via injected instructions in the invite content. The browser navigates the filesystem and exfiltrates files.
The interesting part: traditional runtime path-based controls would not have caught this. As Simon Shine pointed out, all major runtime security tools (AppArmor, Tetragon, Seccomp-BPF, Falco, KubeArmor) gate on executable path, not on content. The agentic browser was using its legitimate, authorized file access. The execution path was correct. The behavior was not.
Then there's hackerbot-claw, documented by Ilya Kabanov. An autonomous bot powered by Claude Opus 4.5 scanned 47,000 public repositories for vulnerable GitHub Actions workflows, selected six targets, and achieved remote code execution in four of them, including repos maintained by Microsoft, DataDog, and CNCF. It used known attack techniques through legitimate CI/CD paths. Nothing about the execution was unauthorized from an infrastructure standpoint. The agent's actions were the problem, not the infrastructure's permissions.
The common thread is clear: the agent's behavior was the vulnerability. Not the network. Not the authentication. Not the infrastructure.
Why runtime enforcement alone doesn't solve this
The people building enforcement layers are doing necessary work. But the current discourse overindexes on enforcement as the primary solution. The sequence matters.
Aldo Pietropaolo has been writing a thoughtful series on Deterministic Control Planes for agent runtime governance. His core argument is sound: you shouldn't ask the agent to enforce its own governance. A control plane should sit outside the agent, evaluate every action using deterministic policy engines (not probabilistic LLM reasoning), and fail closed if unavailable.
This is solid architecture. But a control plane needs to know what to block. Where do those policies come from? If you haven't tested the agent adversarially, you don't know its failure modes. Your policies are based on assumptions, not evidence.
Eran Sandler's AgentSH takes a different angle: execution-layer security between intent and real-world side effects. His critique of AGENTS.md is valid. A markdown file cannot enforce behavior. Models are probabilistic, key instructions get missed or diluted, and there's no mechanism to prevent an agent from ignoring its own rules. AgentSH catches abuse at the process, file, and network level.
What it cannot catch is an agent that stays within its legitimate execution paths while violating its intended behavioral scope. The PleaseFix attack is exactly this scenario.
Simon Shine's observation deserves repeating because it crystallizes the architectural gap. Every major runtime security tool in the container ecosystem gates on executable path. This is a reasonable tradeoff for traditional workloads, where processes follow predictable execution patterns. But AI agents can invoke legitimate tools for illegitimate purposes. They can use authorized paths to perform unauthorized actions. Path-based enforcement cannot distinguish between a legitimate file read and an exfiltration-motivated file read when both use the same system call from the same binary.
This isn't a criticism of these approaches. It’s an observation that they solve a different problem. Infrastructure enforcement protects systems from agents. Behavioral testing validates whether the agents themselves behave correctly under pressure. Both are necessary. But one is the precondition for the other.
What behavioral testing actually tests (and what it doesn't)
It’s important to be specific about what behavioral testing covers.
Adversarial testing for AI agents operates at the conversation layer, not the network layer. It tests for prompt injection, jailbreaks, tool abuse, data exfiltration, and scope violations through crafted dialogue, not through network exploits or binary fuzzing. The attack vector is language. The defense being tested is the agent's ability to maintain its intended behavior when someone is actively trying to make it deviate.
Agentic multi-turn testing extends this to agents with tool access. Instead of single-turn prompt injection, you simulate realistic attack chains: a multi-step conversation that starts innocuously and gradually escalates toward a scope violation or tool misuse. This is closer to how real adversaries operate against AI systems. They don't send a single malicious prompt. They build context, establish rapport, and progressively push boundaries.
The evaluation layer matters too. An LLM-as-a-Judge approach provides structured verdicts (pass/fail/violation) with confidence scores, rather than the binary exploit/no-exploit of traditional pentesting. This is important because AI agent failures exist on a spectrum. An agent that slightly overshares is different from one that exfiltrates credentials, and your testing framework needs to capture that granularity.
What behavioral testing does not cover: it does not test what the agent does to the system at the infrastructure level. File operations, API calls, network access, process execution. That is genuinely the domain of execution-layer enforcement tools. If an agent is writing malicious files or making unauthorized network calls, behavioral testing at the conversation layer won't catch that.
This is where enforcement layers complement testing. The two are not alternatives. They are different phases of the same lifecycle.
The lifecycle that works: test, learn, enforce, monitor, retest
Testing, enforcement, and monitoring are not independent activities. They form a feedback loop where each phase makes the next one better.
At Humanbound, we built the ASCAM (AI Security Continuous Assurance Model) engine around this insight. Rather than treating testing as a one-off event, it operates as a continuous decision loop that evaluates an agent's security posture and selects the right activity at the right time:
- Scan - extracting scope, risk profile, and establishing a security baseline.
- Assess - structured red teaming to build a custom threat model for the agent.
- Investigate - targeted retesting of identified weaknesses, regressions, and emerging threat classes.
- Monitor - continuous drift detection and sentinel testing for behavioral regressions in production.
These aren't sequential phases that run once. A decision engine evaluates multiple signals each cycle - critical findings, posture changes, coverage gaps, behavioral drift - and routes to whichever activity the agent's current state demands. A regression in a previously-secure area triggers investigation. A model update triggers reassessment. Stable posture stays in monitoring. The system self-prioritizes.
The attack methodology is particularly important. Rather than relying on static test suites, the system uses adaptive strategies that learn from every engagement. Each conversation is scored in real time: strategies that make progress toward breaking the agent are refined and escalated, while approaches that hit hard refusals are deprioritized or pivoted mid-conversation. Successful attack patterns are extracted, generalized, and reinjected into future test cycles. Strategies that prove consistently ineffective are retired. The attack library grows with every test run - not through manual curation, but through a self-learning loop that captures what actually works against each specific agent.
This is closer in spirit to coverage-guided fuzzing than to a traditional pentest checklist. The system prioritizes unexplored attack surfaces rather than repeating known patterns. But unlike static fuzzing, it adapts its approach based on the agent's live responses, building on what it learns within and across conversations.
The result: the system discovers failure modes you wouldn't write test cases for, because the adaptive process explores the space more broadly than a human-authored test suite.
The guardrails export step closes the loop. Findings from adversarial testing become firewall rules through Adaptive Context Defense (ACD). Testing directly trains the runtime defense layer. The more you test, the better your firewall gets. And when the firewall blocks something in production, that signal feeds back into the next testing cycle.
Drift detection is what makes continuous assurance practical. Agents change constantly. Models get updated. System prompts get tweaked. Tool permissions shift. The agent you tested in January is not the agent running in March. Without drift detection, your testing results are point-in-time snapshots that decay in value. With it, behavioral regressions trigger re-assessment automatically.
The 14.4% problem
The data makes the case more clearly than any architectural argument.
Gravitee's State of AI Agent Security report found that only 14.4% of AI agents go live with full security approval. The AIUC-1 Consortium, with input from CISOs at Confluent, Elastic, UiPath, and Deutsche Borse, documented that 80% of organizations report risky agent behaviors including unauthorized system access and improper data exposure. Only 21% of executives have visibility into agent permissions, tool usage, or data access patterns.
The math tells the story: 85.6% of agents ship without full security approval. 80% of organizations already see risky behaviors.
Enforcement architecture is meaningless for agents that were never tested before deployment. You can build the most sophisticated control plane in the world, but if the agent it governs was never validated against adversarial conditions, your enforcement policies are based on what you hope the agent does, not what you've proven it does.
As David Campbell put it: "Testing for prompt injection doesn't automatically mean you're safe." That’s true. But not testing at all definitely means you're not.
What to do this week
For practitioners, the actionable version is straightforward.
- Inventory your deployed agents. Most organizations have more than they think. The AIUC-1 data suggests an average of 1,200 unofficial AI applications per enterprise. You cannot test or govern what you haven't discovered.
- Run adversarial tests before adding enforcement layers. If you haven't tested your agents with agentic multi-turn attack scenarios, start there. Scope violations, tool abuse, and data exfiltration through conversation are the failure modes that infrastructure enforcement will not catch.
- Map your findings to OWASP Agentic AI categories. NIST's AI Agent Standards Initiative just closed its RFI on agent security (March 9), and the identity/authorization concept paper is open for comment until April 2. What NIST publishes in 2026 will appear in compliance frameworks by 2027. Building your evidence base now, with posture scores and OWASP-mapped findings, positions you ahead of the compliance curve rather than scrambling to catch up.
- Treat behavioral testing as a CI/CD gate, not an annual audit. Agents change weekly. Testing cadence should match deployment cadence. A gate that blocks insecure deployments is worth more than a quarterly report that documents them after the fact.
The enforcement conversation is important. Control planes, execution-layer security, agent identity chains. All of it matters. But enforcement for untested agents is enforcement in the dark.
The sequence matters:
- Test first.
- Learn what breaks.
- Enforce based on evidence.
- Monitor for drift.
- Retest.
What does your team's testing cadence look like today?