

Your Agent Passed Its Security Test. That Was Three Weeks Ago.
I come from the software world, not the security world. I spent years building products and working with AI before Humanbound existed. So when I started paying attention to how the security industry approaches AI agent testing, I noticed something that felt immediately familiar: they're applying the same pattern that worked for traditional software. And I think it's hitting a wall.
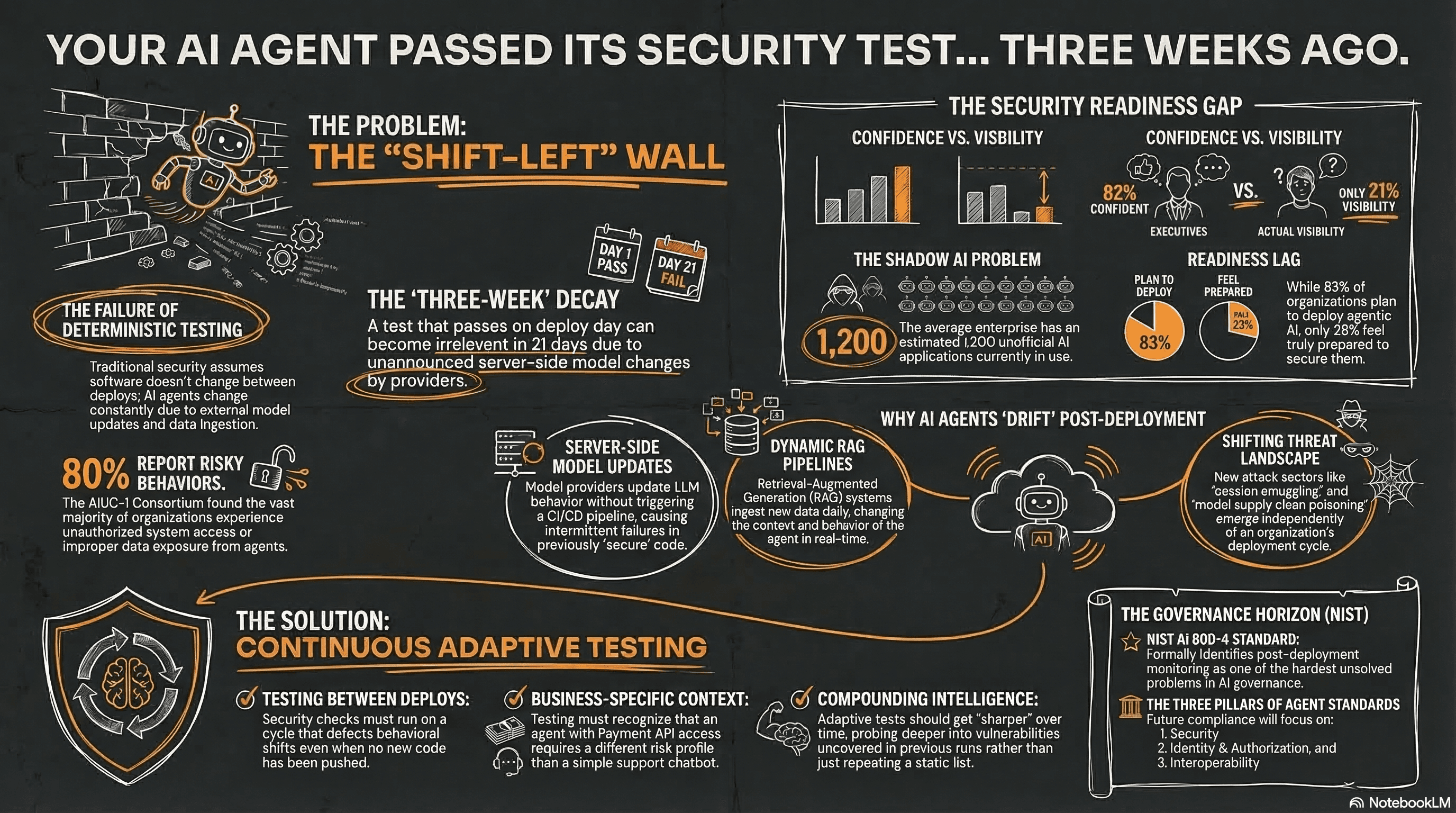
The pattern is shift-left. The idea is to catch security issues earlier in the development lifecycle by integrating testing into your CI/CD pipeline so it runs automatically on every deploy. It's a sensible approach. It worked well for deterministic software.
But from where I sit, building tools that test AI agents every day, I keep seeing the same thing: the test passes on deploy, and three weeks later something breaks in production that the test never saw. Not because the test was bad. Because the system changed and nobody re-tested.
A familiar pattern, a different problem
Here's how agent security testing typically works today. You pick an eval framework, something like PromptFoo, Garak, or a custom suite. You define test cases: adversarial prompts, boundary checks, expected behaviors. You map them to OWASP categories. You wire the whole thing into CI/CD. On every deploy, the tests run. If they pass, you ship.
This is genuinely useful. A year ago, most teams weren't testing their AI systems at all. Having structured, automated testing in the pipeline is real progress.
But the data suggests it's not enough.
Gravitee's State of AI Agent Security 2026 report surveyed over 900 executives and practitioners. Only 14.4% of AI agents go live with full security and IT approval. Meanwhile, 82% of executives feel confident their existing policies protect them from unauthorized agent actions, even though only 21% have visibility into what agents actually do.
The AIUC-1 Consortium briefing, developed with Stanford's Trustworthy AI Research Lab and input from CISOs at Confluent, Elastic, UiPath, and Deutsche Borse, found 80% of organizations reported risky agent behaviors including unauthorized system access and improper data exposure. The average enterprise has an estimated 1,200 unofficial AI applications in use.
Cisco's State of AI Security 2026 paints a similar picture: 83% of organizations plan to deploy agentic AI capabilities. 29% feel ready to secure them.
Whichever report you look at, the gap between deployment speed and security readiness keeps showing up.
What I think the security world is underestimating
Coming from the AI side, there's something about how agents work that I think the security testing model hasn't fully internalized yet.
Traditional software doesn't change between deploys. You test it, you ship it, it behaves the same way tomorrow. That's what makes CI/CD-integrated testing so effective. The thing you tested is the thing running in production.
AI agents break this assumption in ways that feel obvious to anyone who's built with LLMs, but I think they're still surprising to security teams used to deterministic systems.
Models update server-side without triggering your CI pipeline. A developer documented this exact scenario on DEV Community last week: their eval suite passed on deploy, then three weeks later the model provider updated the model's behavior. No announcement. No code change. No CI trigger. Production started failing intermittently. They didn't trace it to a model change until day 26.
RAG pipelines ingest new data daily. Context windows fill differently based on production traffic. Tool availability changes. The agent you tested on deploy day is genuinely not the same agent running three weeks later. Anyone who's built AI systems knows this intuitively, but the testing model still assumes a static target.
And then the threat landscape moves independently of all of this. Cisco's report documents attack techniques that barely had names eighteen months ago: impersonation attacks between agents, session smuggling, unauthorized capability escalation, model supply chain poisoning. The tests you wrote last quarter weren't designed for these.
A question worth asking more often
I think most organizations are currently asking: "Did we test it?"
What I find more interesting is: "When was the last test, has anything changed since, and would we catch it if it had?"
NIST AI 800-4, published March 6, formally identifies post-deployment monitoring of AI systems as one of the hardest unsolved problems in AI governance. They cataloged six monitoring categories and a long list of gaps, barriers, and open questions. The message is clear: the industry doesn't yet have reliable methods for monitoring AI systems after they go live.
This has a practical side too. The compliance timeline is beginning. NIST's AI Agent Standards Initiative has three pillars: security, identity and authorization, and interoperability. Their CAISI RFI on agent security closed March 9 with 932 comments. The NCCoE identity concept paper is open until April 2. Listening sessions on sector-specific barriers start in April.
I think when auditors and regulators start asking questions, they'll want to see what the agent's security looks like now, not what it looked like at the last deploy. And that's a different kind of evidence than a point-in-time test report.
What "continuous" actually means
I want to be specific here, because I've seen "continuous" become a marketing word that means "we run the same thing on a cron job."
If your test suite checks for the same 50 jailbreak patterns every Tuesday, and a new attack class emerged on Wednesday, you'll miss it for the same reason you'd miss it with a manual audit. The tests don't know what they don't know. Repetition and adaptation are different things.
What I think the industry actually needs, and what we're trying to build at Humanbound, is testing that does three things most current approaches don't fully do.
It needs to run between deploys, not just on deploy. If a model changes server-side or a RAG pipeline ingests something unexpected, the testing should catch the behavioral shift without waiting for someone to push code.
It needs to understand context. A generic OWASP scan is useful as a baseline, but the serious failure modes are business-specific. An agent with payment API access has a fundamentally different risk profile than one answering support questions, and the testing should reflect that without requiring someone to manually configure every scenario.
And it needs to get sharper over time. If a test run uncovers a specific class of vulnerability, the next run should probe deeper in that direction rather than starting from scratch. The intelligence should compound.
I'll be honest: the industry is early here. Most organizations are still at step one, which is getting any structured testing into their pipeline. Moving to continuous adaptive testing is step two. Very few are there yet, including most of our customers. But I think the direction is clear.
The question I keep thinking about
There's a question I think will eventually land on every team that has AI agents in production: "What would happen if one of those agents were compromised right now?"
It's a simple question, but I think most organizations would struggle to answer it with anything concrete. They could point to policies, inventories, training records, maybe a test report from the last deploy. But actual evidence of what the agent is doing today, right now, in production? That's harder.
And that question could come from anywhere. A board member who read the Cisco report. An auditor responding to NIST's new standards timeline. A customer filling out a security questionnaire. Or, less pleasantly, from an incident.
The organizations that can answer with current evidence will be the ones that move fastest. The ones that can't will find themselves explaining a gap they didn't know they had.
I don't think the answer is to stop shipping. The whole point of what we do at Humanbound is to help organizations ship AI with confidence. But confidence that's based on a test from three weeks ago isn't confidence. It's hope. And as anyone who's shipped software knows, hope is not a strategy.
About the author
Co-founder of Humanbound, an AI security testing platform helping enterprises secure their AI agents. Based in Athens, Greece.